


The company formerly known as Facebook made some big announcements yesterday, working with Intel that could provide some of the powerful AI hardware to power Meta’s new AI products. The we. The big new thing to know is the Llama 3 AI model and Meta’s new AI assistant, simply called “Meta AI.”
Meta’s Llama family of large-scale language models remains open source, despite competing in performance with closed-source leaders such as OpenAI’s ironically named GPT series and Google’s Gemini family. It’s worth noting that. The latest version of Llama is Llama 3, which comes in two versions, one with 8 billion parameters and one with 70 billion parameters.
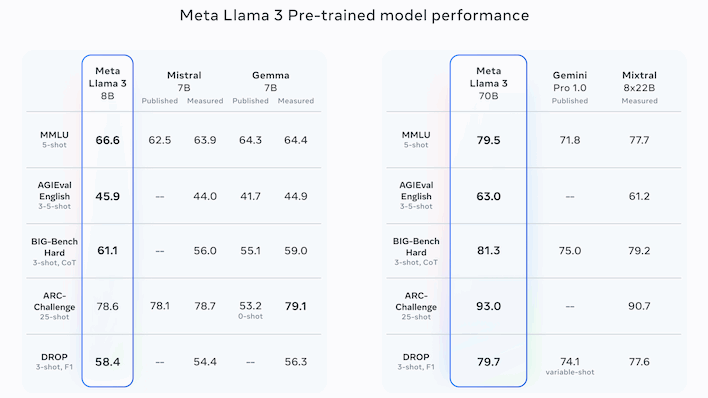
Going off the benchmarks presented by Meta itself, the full version with 70B parameters seems to be roughly competitive with OpenAI’s GPT-4 (not a comparison made by Meta itself). Instead, the company seems to be focusing on comparisons with less popular rivals, such as Google’s Gemini and Gemma models, Anthropic’s Claude 2, and France’s Mistral AI’s Mistral and Mixtral models.
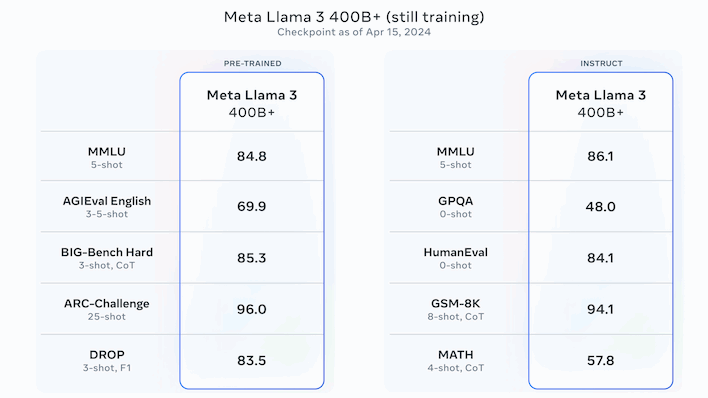
Overall, the numbers are compelling, but Meta isn’t done with the LLM just yet. According to Mehta, the largest version of Rama 3 he has over 400 billion parameters and is still in training. The numbers above are for that model, and are probably the best overall we’ve seen from what would be an open source release. Meta said Llama 3 is expected to receive additional releases “in the coming months” adding features such as multimodality (images, audio, and possibly video), multiple language support, and longer context windows. .
Best of all, Llama 3 is open source, so you can download the model now and play with it locally. However, there is a caveat to this. The download requires the use of a shell script, so you will need to set up a Bash environment. This should be easy for AI researchers, most developers, and many power users, but if you’re a casual AI enthusiast, you might want to wait for a more accessible package.
Sure, if you’re an AI researcher, this is all well and good, but what about regular users? Well, you can (in theory) use Meta’s new Meta AI assistant. You can try Llama 3. The assistant is built into the latest versions of her Facebook, Instagram, WhatsApp, and Messenger apps and can perform functions such as finding recommended restaurants, nightlife activities, educational assistance, and image generation. You can also play on the new site Meta.ai, but you’ll need a Facebook account to do anything interesting. I could not access the site even after logging in.
One downside to this reconfiguration is that Meta’s Imagine AI generation functionality has been incorporated into the new Meta AI site. Previously, users were allowed to log in with their Meta account, but image generation now requires their Facebook account, allowing anonymous users to attack Meta’s servers with computationally expensive image generation requests. may be prevented. However, we learned some new tricks, such as the ability to take the images we create, iterate on them, animate them, and allow users to share them with their friends in his GIF format. That’s pretty cool.
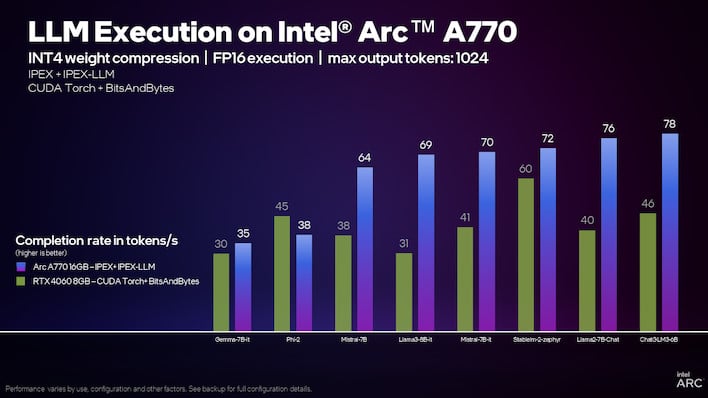
Intel says the Arc A770 is significantly faster than the RTX 4060 on large language models.
Intel’s behind-the-scenes role in Meta’s new AI efforts isn’t entirely clear, but Intel is working hard on them nonetheless. The company announced multiple releases and articles boasting the high performance of Core Ultra and Xeon CPUs, Arc GPUs, and Gaudi accelerators running Llama 3.
In particular, the company claims that Arc GPUs integrated into Core Ultra CPUs are “already [text] An 8-pack of Gaudi 2 chips, on the other hand, appears to be able to generate about 131 sentences per second while running 10 prompts at once. The upcoming Xeon 6 processor seems to be twice as fast as his Sapphire Rapids. Llama 3 too.
As far as the Arc discrete GPU is concerned, Intel actually has an extended tutorial that shows you how to set up large language models to run locally on the Arc GPU. We covered this when Intel first announced it, but the end result so far seems to be fairly user-friendly, despite the fairly complex setup process. If you have an Arc GPU and want to chat with LLM running directly on your PC, visit Intel’s walkthrough guide.